
Quelle: Experian
KI unter Kontrolle
Produkte, die künstliche Intelligenz (KI) nutzen, sollen gesetzeskonform entwickelt werden und nachvollziehbare Ergebnisse liefern. Ein Audit des Fraunhofer IPA hat nun einem Produkt der Firma Experian – dem »Fraud Miner« als Teil einer Betrugspräventionslösung – diese Eigenschaften bestätigt.
Veröffentlicht am 27.10.2022
Lesezeit ca. 12 Minuten
KI in der Datenanalyse eröffnet in vielen Branchen neue Möglichkeiten. Gleichzeitig kann die Technologie verunsichern und ethisch relevante Fragen aufwerfen. Besonders im Fokus sind das maschinelle Lernen (ML) und die dabei verwendeten Algorithmen. Weil ML-Systeme weitgehend eigenständig anhand von Daten lernen und bei vielen Algorithmen die Wirkungszusammenhänge in den resultierenden Modellen nicht offensichtlich sind, spricht man häufig von einer »Black Box«, denn es ist oft nicht nachvollziehbar, wie ein Algorithmus zu einem bestimmten Ergebnis kommt.
Dies kann rechtlich problematisch werden, weil KI durch nationale und europäische Vorhaben stärker reguliert werden wird. Und es mindert das Vertrauen in die Technologie. Um dies zu verbessern, können objektive Methoden sicherstellen, dass ML-Systeme fair, erklärbar und nachvollziehbar arbeiten. Wie das geht, zeigt ein Projekt des Fraunhofer IPA mit dem Informationsdienstleister Experian. Das Institut hat dessen ML-Komponente »Fraud Miner« eines Datenverarbeitungsprodukts für den Online-Handel hinsichtlich einer gesetzeskonformen Entwicklung und der Nachvollziehbarkeit der Ergebnisse untersucht. Die eingesetzte Methodik ist für nahezu alle Branchen und KI-basierten Produkte anwendbar.
Maschinelles Lernen in der Betrugsprävention
Der Fraud Miner hat das Ziel, Betrugsversuche im Internet zuverlässig zu erkennen. Bisher genutzte Systeme erkennen meist zu viele Betrugsversuche, die sich am Ende als »False Positive« herausstellen, also fälschlicherweise als Betrug deklariert wurden. Laut der Payment-Beratung CMSPI lagen 2020 die Umsatzverluste durch tatsächlichen Kartenbetrug in Europa bei etwa zwei Milliarden Euro, die Verluste durch False Positives und hierdurch erforderliche manuelle Kontrollen hingegen bei rund 23 Milliarden Euro.
Experian hat darum in Deutschland die Betrugspräventionslösung Aidrian entwickelt, deren Machine-Learning-Komponente, der Fraud Miner, Betrug zuverlässiger erkennen und die Anzahl von False Positives so signifikant reduzieren soll. Um sicherzustellen, dass die Lösung gesetzeskonform ist und nachvollziehbare Ergebnisse liefert, wollte Experian den Transaction Miner einem unabhängigen Audit unterziehen. Mit diesem Anliegen trat das Unternehmen 2021 an das Fraunhofer IPA heran.
Wie prüfen?
Noch gibt es keine genauen Vorgaben für die Überprüfung eines ML-Systems oder gar offizielle Standards. Die wichtigsten Ansätze für die Entwicklung eines verbindlichen Regelwerks kommen vom TÜV Austria, dem Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS und der Europäischen Kommission. Letztere versucht aktuell, mit ihrem Entwurf für ein »Gesetz über Künstliche Intelligenz« Leitlinien für die Entwicklung von KI-Anwendungen zu schaffen. Diese sind jedoch oftmals zu abstrakt und enthalten kaum konkrete Anforderungen an Unternehmen und Fachkräfte.
Der TÜV Austria stellt zusammen mit der Universität Linz in einem White Paper Ansätze zur Zertifizierung von ML-Systemen vor. Ein wesentlicher Teil ist ein Katalog zur Auditierung eines ML-Systems, der bestehende Kriterien aus der Softwareentwicklung einfließen lässt und auch ethische Fragen adressiert. Der Katalog beschränkt sich zwar auf Problembereiche wie überwachte Lernverfahren und weitgehend unkritische Anwendungen, legt aber einen Grundstein für weitere Zertifizierungsbemühungen.
Der zurzeit ausführlichste Vorschlag für das Audit eines ML-Systems ist der »Leitfaden zur Gestaltung vertrauenswürdiger Künstlicher Intelligenz« des Fraunhofer IAIS. Er beinhaltet unter anderem Vorgaben für die strukturierte Identifikation KI-spezifischer Risiken in Hinblick auf die sechs Dimensionen der Vertrauenswürdigkeit: Fairness, Autonomie und Kontrolle, Transparenz, Verlässlichkeit, Sicherheit und Datenschutz. Darüber hinaus bietet er eine Anleitung zur strukturierten Dokumentation von technischen und organisatorischen Maßnahmen entlang des Lebenszyklus einer KI-Anwendung, die dem aktuellen Stand der Technik entsprechen. Alle drei genannten Werke gaben wichtige Orientierungspunkte für das Audit des Transaction Miners.
Technische Erklärbarkeit
Technische Verfahren können aufzeigen, ob ein System wie der Fraud Miner nachvollziehbare und faire Entscheidungen trifft. So hat sich beispielsweise die Anwendung sogenannter Surrogatmodelle bewährt, einer Simulation des ursprünglichen Modells. Eine andere Methode besteht in kontrafaktischen Erklärungen. Diese zeigt auf, wie die Ergebnisse von den Eingabedaten abhängen. Darüber hinaus ist der »Shapley Additive exPlanations«-Ansatz (SHAP-Ansatz) zu nennen, der Konzepte aus der Spieltheorie nutzt. Mit diesem wird beispielsweise die Vorhersage eines bestimmten Wertes erklärt, indem der gerechte Beitrag jedes Merkmals zur Vorhersage berechnet wird. Empfehlenswert ist rund um die Erklärbarkeit auch, zwei Blickwinkel anzusetzen: die globale Erklärbarkeit eines Modells zur Darstellung der wichtigsten Treiber und Wirkungszusammenhänge sowie die lokale Erklärbarkeit, die zu dem Ergebnis in einem bestimmten Fall führt.
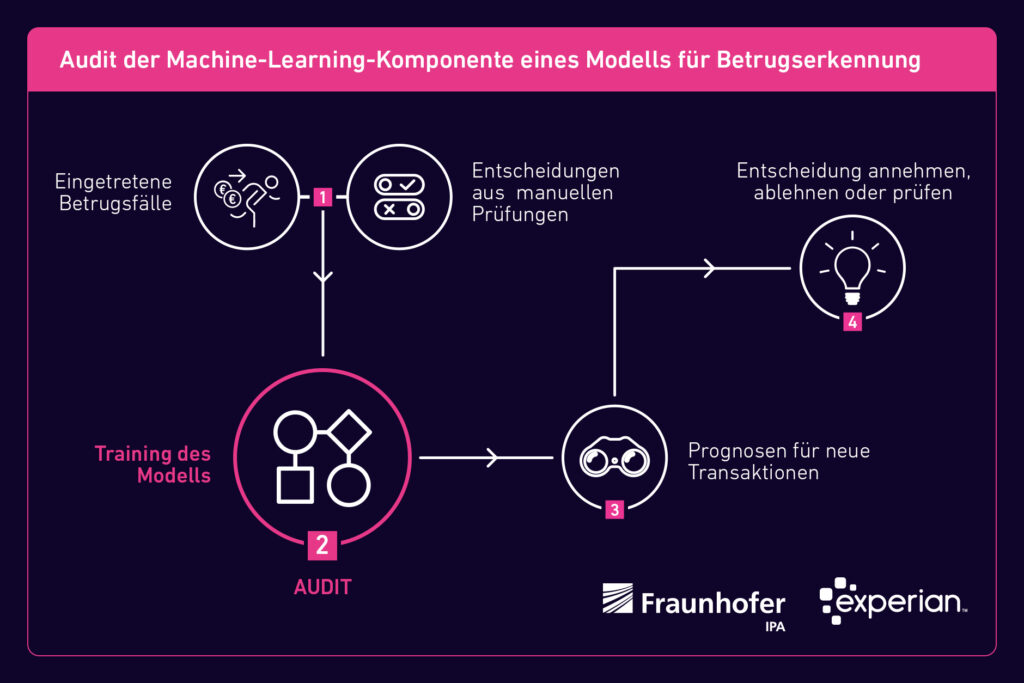
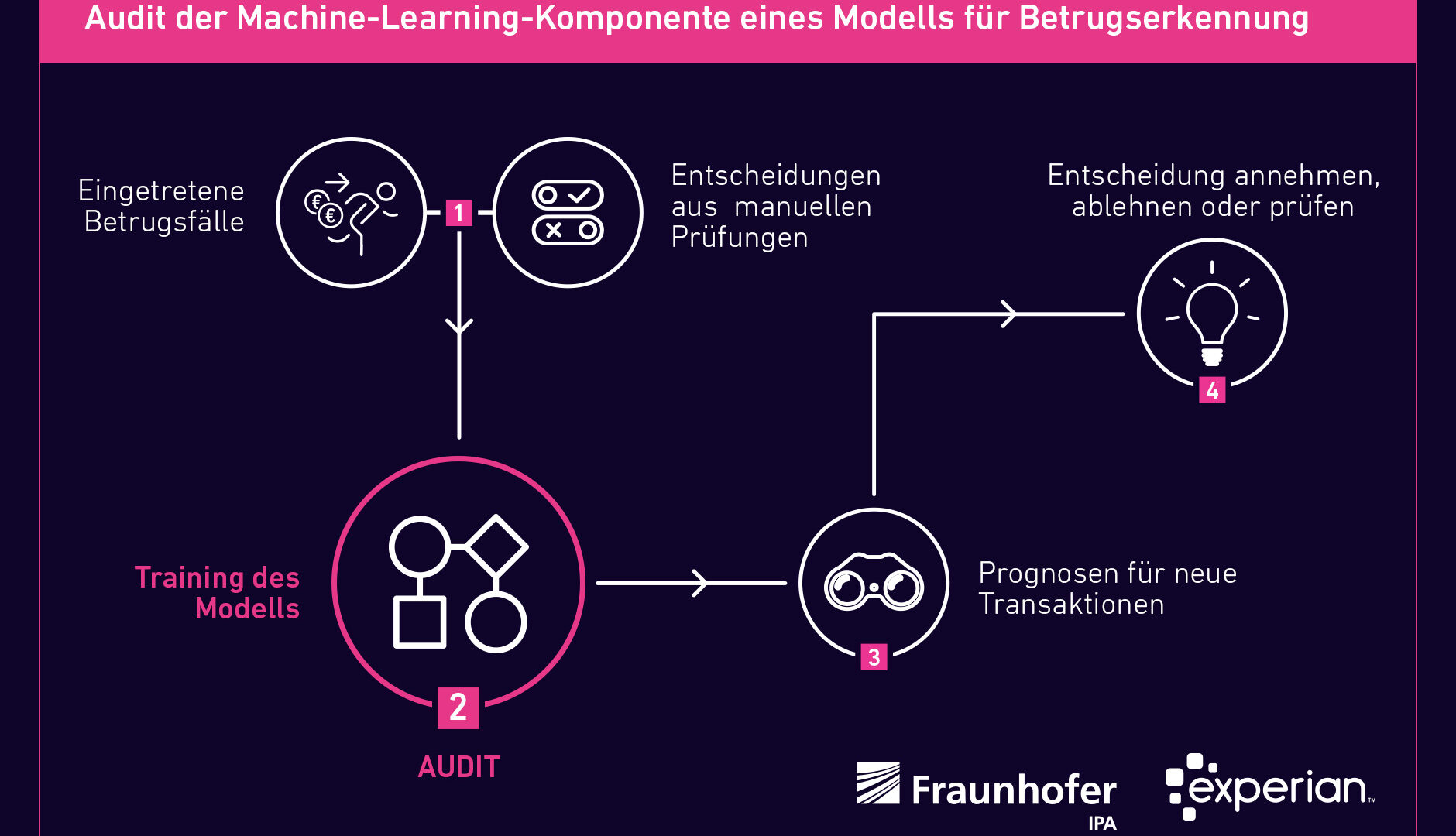
Derartige Methoden reichen in der Praxis aber oft nicht, weil sie immer nur Aussagen für ein bestimmtes Modell treffen können. Bei einem Produkt wie dem Fraud Miner kommen aber je nach Kunden unterschiedliche Modelle zum Einsatz. Darüber hinaus müssen die Modelle beim Fraud Miner regelmäßig erneuert werden, um sie an die sich schnell verändernden Vorgehensweisen der Betrüger anzupassen. Das Audit des Fraud Miners hat sich deshalb auf vier Komponenten konzentriert, die der eigentlichen Modellentwicklung zugrunde liegen.
Komponente 1: Feature Engineering
Bei der Beurteilung des Feature Engineering geht es vor allem darum, gängige Fehlerquellen auszuschließen. Gängige Fehlerquellen sind Target Leaks oder Trainingsdaten, die versehentlich im Testset vorhanden sind, oder undurchsichtige Feature-Transformationen. Bei einem Target Leak sind Informationen der Zielvariable bereits in den Features vorhanden: Beispielsweise soll die Lebensdauer einer Batterie in Jahren berechnet werden, die Features enthalten allerdings schon die Lebensdauer in Wochen. Das Fraunhofer IPA sah in diesem Fall weder eine Gefahr von Target Leaks noch die Gefahr von Leaks der Trainingsdaten ins Testset. Auch die angewendeten Feature-Transformationen wurden als transparent bewertet.
Komponente 2: Modellauswahl und Training
Wie erwähnt stehen beim Fraud Miner regelmäßig die Auswahl, das Training und die Kalibrierung eines aktualisierten Modells an, damit das System die neuesten Betrugsmuster zuverlässig erkennt. Bei der Modellauswahl standen ursprünglich drei Modelle zur Auswahl, deren Hyperparameter durch einen evolutionären Algorithmus bestimmt werden. Hyperparameter sind die Parameter des Modells, die zur Steuerung des Trainingsalgorithmus verwendet werden und deren Werte im Gegensatz zu anderen Parametern vor dem eigentlichen Training des Modells festgelegt werden müssen. Hyperparameter können also beispielsweise die Anzahl der Schichten in einem neuronalen Netz sein oder die Tiefe eines Entscheidungsbaumes. Am Ende der Modellauswahl wird die Hyperparametereinstellung weiterverwendet, die die genauesten Ergebnisse liefert. Im Anschluss finden das Training des finalen Modells mit den ermittelten Hyperparametern sowie eine Kalibrierung statt.
Beim Training und der Modellauswahl ist zu beachten, dass nach Möglichkeit aktuelle, bekannte Frameworks verwendet werden und die Optimierung bezüglich sinnvoller Metriken stattfindet. Der Einsatz solcher Frameworks sorgt für die notwendige Transparenz und Nachvollziehbarkeit in diesem Schritt. Beim Fraud Miner wurde festgestellt, dass es sich bei allen eingesetzten Methoden um etablierte Verfahren und Frameworks handelt, abgesehen von einer eigens von Experian entwickelten Teilkomponente. Bei deren Einsatz ist eine Dokumentation und Begründung für die Wahl der Methode besonders wichtig. Diese wurden im Audit geliefert.
Komponente 3: Modellevaluation
Nach allen Trainings- und Kalibrierungsschritten erfolgt eine abschließende Evaluation des fertigen Modells auf dem Testdatenset. Am Ende eines vollständigen Trainingszyklus wird die »Konfusionsmatrix« für das jeweilige Klassifikationsproblem erstellt. Aus dieser Matrix lässt sich beispielsweise die False-Positive-Rate ablesen. Zudem wird ein Kalibrierungsreport erzeugt. Dieser liefert wirtschaftliche Kennzahlen wie beispielsweise die Märkte und Anwendungsszenarien des jeweiligen Kunden mit Gewinn- und Verlustrechnungen. Darüber hinaus ist der Report wichtig, weil er Fairness in Form von Fehlerraten bezüglich sensibler Gruppen berücksichtigt.
Komponente 4: Menschliche Kontrolle
Das Unbehagen gegenüber KI und maschinellem Lernen beruht auch auf der Vorstellung, technische Systeme würden sich in permanenten Selbstoptimierungsschleifen weiterentwickeln. Die Experten des Fraunhofer IPA sahen in diesem Fall jedoch keine Probleme. Bei der Modellentwicklung und -evaluation sind menschliche Experten und Risikoprüfer beteiligt und prüfen das Modell auf die Plausibilität der Ausgaben. Ebenso obliegt die finale Entscheidung immer einem Menschen.
Fazit
Das Fraunhofer IPA bestätigte dem Fraud Miner sehr hohe Qualität während des gesamten Entwicklungsprozesses und in der Bewertung von Transaktionen. Das System trifft zuverlässige und für Experten nachvollziehbare Vorhersagen, die zu verbesserten Entscheidungen führen. Weil momentan noch allgemein etablierte Standards für die Zertifizierung von ML-Systemen fehlen, können Fairness und Nachvollziehbarkeit der Resultate des Fraud Miner noch nicht offiziell zertifiziert werden. Das Audit kommt einer solchen Zertifizierung aber möglichst nahe und hat die Grundlage für die Entwicklung standardisierter Prüfverfahren geschaffen.
Arbeiten wie diese sind Teil des Forschungsschwerpunkts »Zuverlässige KI« der Abteilung Cyber Cognitive Intelligence (CCI) des Fraunhofer IPA, in dessen Kontext die Forscher Unternehmen rund um KI-Entwicklungen beraten und unterstützen sowie KI-Anwendungen umsetzen. Ein Audit wie das beschriebene ist branchenübergreifend für nahezu alle KI-basierten Anwendungen umsetzbar.
»Durch maschinelles Lernen stehen uns neue Werkzeuge zur Verfügung«
Ein Interview mit Martin Baumann, Director Analytics bei Experian

Herr Baumann, welche Potenziale sehen Sie in KI und genauer dem maschinellen Lernen allgemein und speziell für Ihr Unternehmen?
Selbst wenn wir von künstlicher Intelligenz, wie Hollywood sie präsentiert, noch weit entfernt sind, beeindrucken schon heute die Möglichkeiten, die KI und maschinelles Lernen eröffnen. Denken wir zum Beispiel an sprechende Geräte oder die Gesichtserkennung beim Smartphone sowie an Prozessautomatisierung im Posteingang oder das Erkennen von Auffälligkeiten in der Sensorik. Diese Anwendungen haben in den Alltag von Privatpersonen und Unternehmen Einzug gehalten und sind nicht mehr wegzudenken. Die weitere Digitalisierung wird zu noch mehr verfügbaren Daten führen, auf die KI und ML aufsetzen. Es gibt Prognosen, die ein zweistelliges Wachstum des weltweiten Bruttoinlandsprodukts bis 2030 allein auf die Nutzung intelligenter Systeme zurückführen. Für Experian ist es insbesondere maschinelles Lernen, mithilfe dessen wir neue Potenziale erschließen. Unseren Data-Scientists stehen bildlich gesprochen neue Werkzeuge zur Verfügung. Damit können wir etwa zusätzliche Datentypen berücksichtigen, Lösungen noch kundenindividueller ausgestalten, komplexere Wirkungszusammenhänge erkennen und in Prognosemodellen abbilden. Operativ betrachtet können wir darüber hinaus effizienter arbeiten. Der Fraud Miner ist ein gutes Beispiel dafür.
Wie haben Sie den Prozess des Audits erlebt und welche Aufwände waren damit verbunden?
Die Mitarbeiter von Fraunhofer IPA haben das Audit sehr professionell durchgeführt. Dem Fehlen genauer Vorgaben für die Überprüfung eines ML-Systems zum Trotz war das Zusammenführen der drei angeführten Leitfäden zu einem Prüfprogramm für uns geräuschlos. Zielgerichtet wurde zunächst der genaue Scope vereinbart. Nach einer allgemeinen Einführung zu Experian und dem Anwendungsfall des Fraud Miners gab es jeweils einen Fokus-Workshop zu den vier Komponenten, in denen die Modellentwickler von Experian als erstes den Prüfern von Fraunhofer das Vorgehen teils bis auf Code-Ebene vorgestellt und dann Rede und Antwort gestanden haben. Falls notwendig, gab es einen Zweittermin oder schriftlichen Austausch, in dem weitere Rückfragen behandelt wurden. Da es sich um eine komplexe Materie handelt, haben wir erwartet, dass ein nennenswerter Aufwand entsteht. Nichtsdestotrotz blieb es Dank der strukturierten Vorgehensweise bei einer überschaubaren Anzahl an Terminen. Hervorzuheben ist, dass die Atmosphäre durchgehend wenig von einer Prüfer-Prüflings-Situation hatte, sondern Gespräche von Experten mit Experten auf Augenhöhe geführt wurden.
Welche Learnings haben Sie und Ihre Firma daraus gezogen?
Das primäre Ziel war die unabhängige Überprüfung des Transaction Miners. Da wir bei Finanzprozessen in einem sensiblen Umfeld agieren, ist es unser Selbstverständnis, dass wir höchsten Ansprüchen genügen müssen. Die Durchsicht durch einen Dritten rundet die langjährige Tätigkeit und hohe Expertise unserer Kollegen ab. Wir waren im Vorfeld der Prüfung schon überzeugt von der sehr hohen Qualität des Fraud Miners. Die Bestätigung im Prüfungsergebnis war dann trotzdem nochmals sehr erfreulich. Die eine oder andere Anregung aus den Fachdiskussionen nehmen wir gerne zukünftig in unsere Standards auf. Dies insbesondere im Hinblick auf das sekundäre Ziel. Es ist davon auszugehen, dass die laufenden Gesetzgebungsverfahren auf europäischer Ebene, etwa der angesprochene EU AI Act, generell für uns wie für viele andere Unternehmen neue Anforderungen bringen wird. Es ist hilfreich zu wissen, dass wir mit unseren Standards schon gut aufgestellt sind.
Herr Baumann, wir danken Ihnen für dieses Gespräch.
Ihr Ansprechpartner
Marco Huber
Wissenschaftlicher Direktor für Digitalisierung und KI
Telefon +49 711 970-1960